


















KV Caching in LLMs: A Guide for Developers
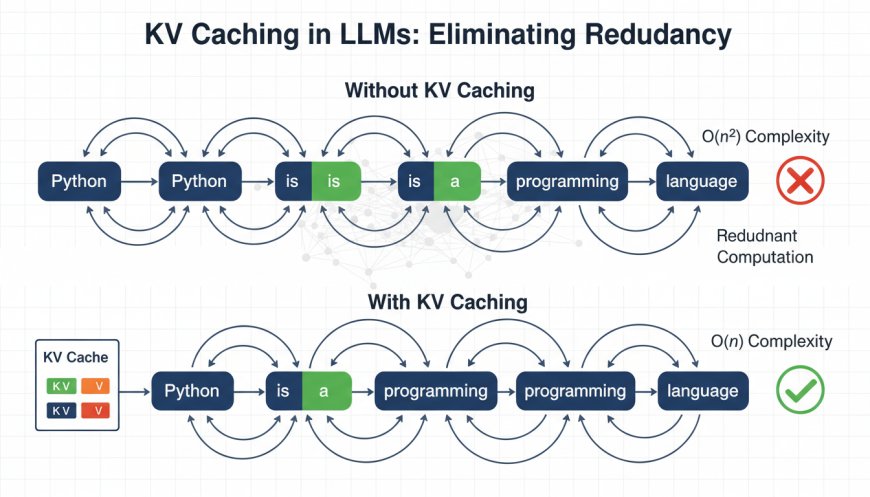
Language models generate text one token at a time, reprocessing the entire sequence at each step.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0









